The pain
When testing the platform, we realized that there was an inaccuracy in the patient's medical summary and tried to understand the reason for that.
Problem statement
A medical summary is the output of a patient-filled medical questionnaire, provided to doctors before treatment. This study emerged from a low metric score of the Diagnostic Robotics medical summary.
The business goal
- Non-accurate medical summaries disqualify the product itself.
- Non-accurate medical summaries lead to wrong ML, which is the company's main objective.
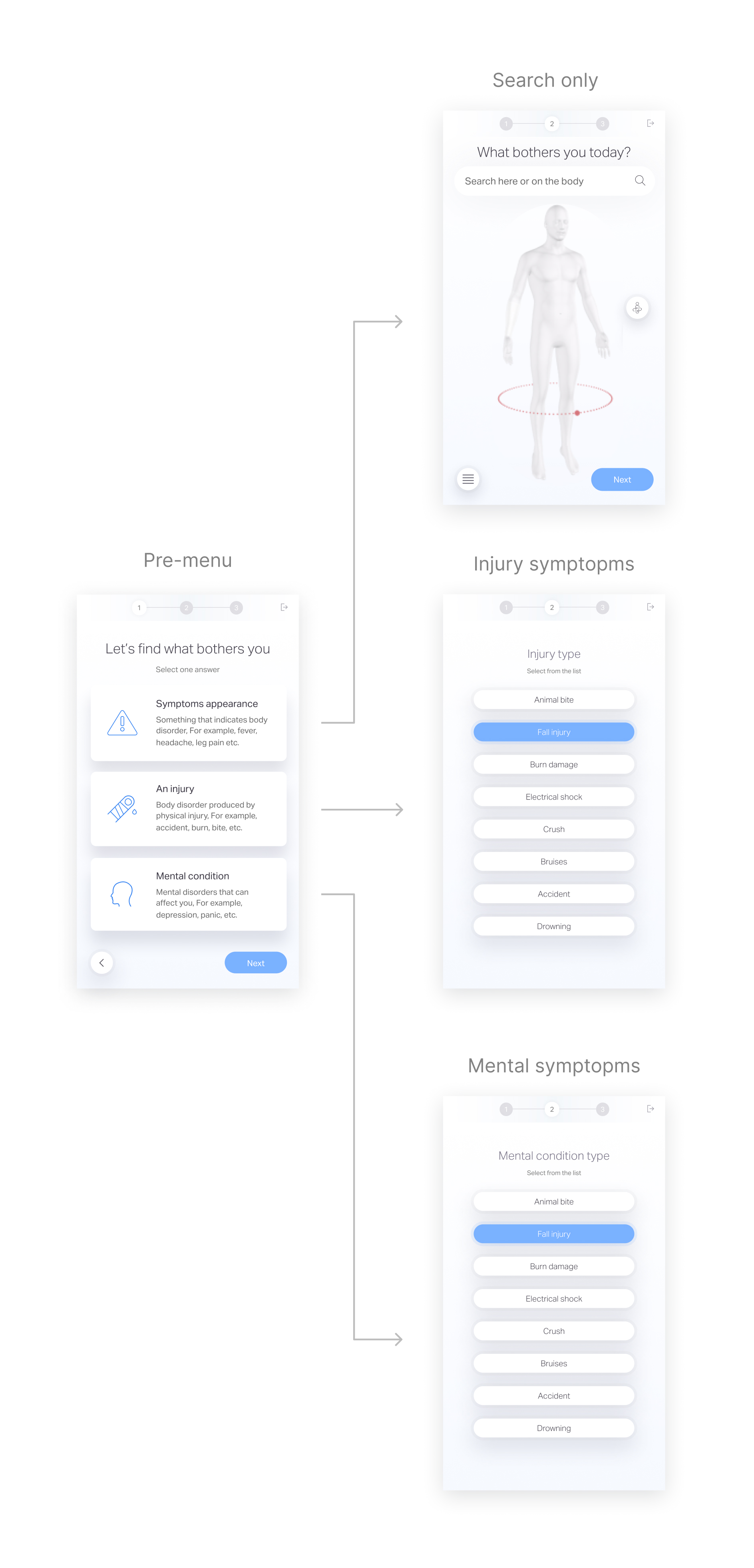
The patient meet the medical questionnaire at ER or home-care (Telemedicine)

The product high level flow
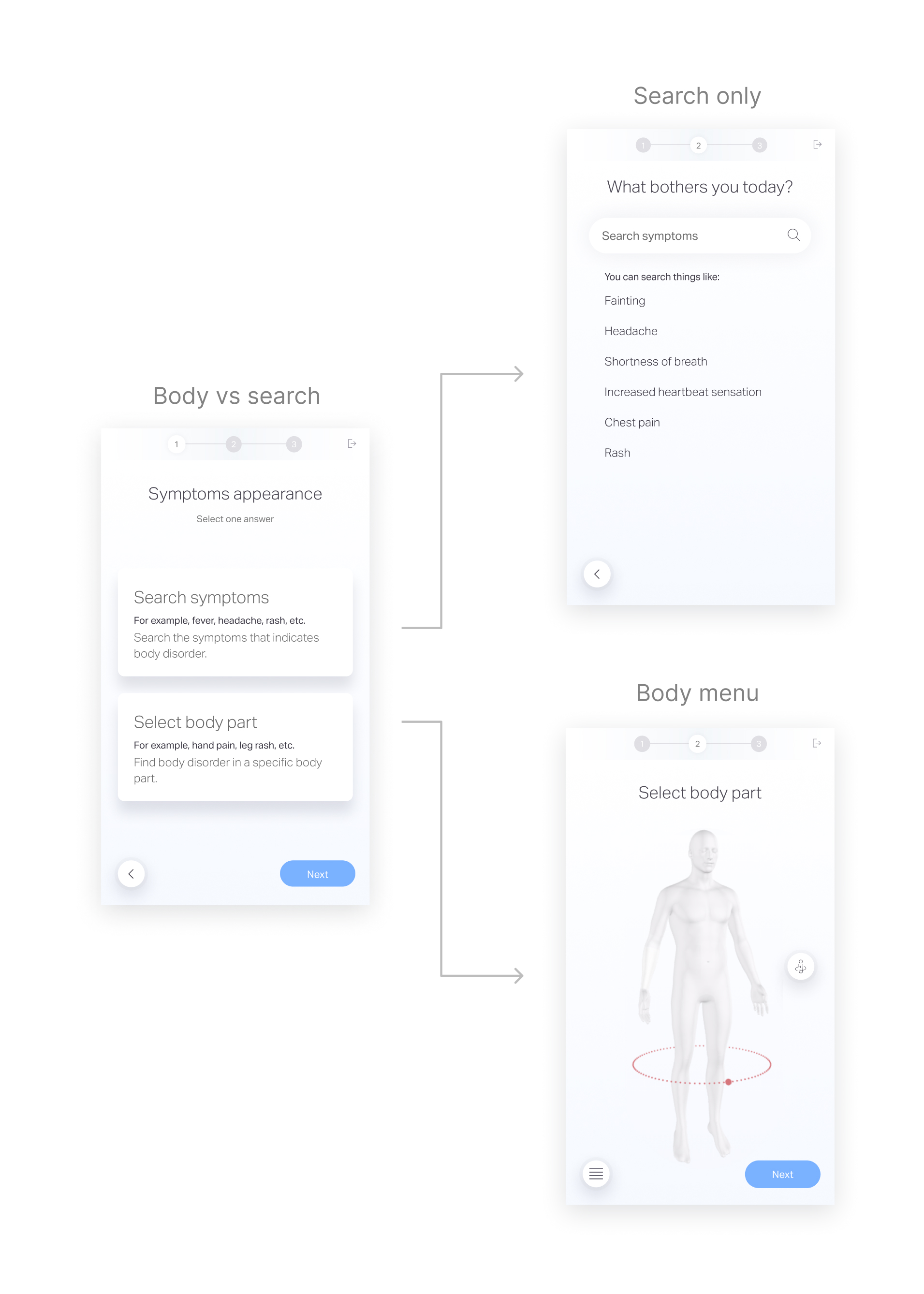
The patient answer demographic questions, choose a symptom that he suffer from and answer medical questionnaire created by a medical team, then his answers goes through ML process and served to the MD as a medical summary.
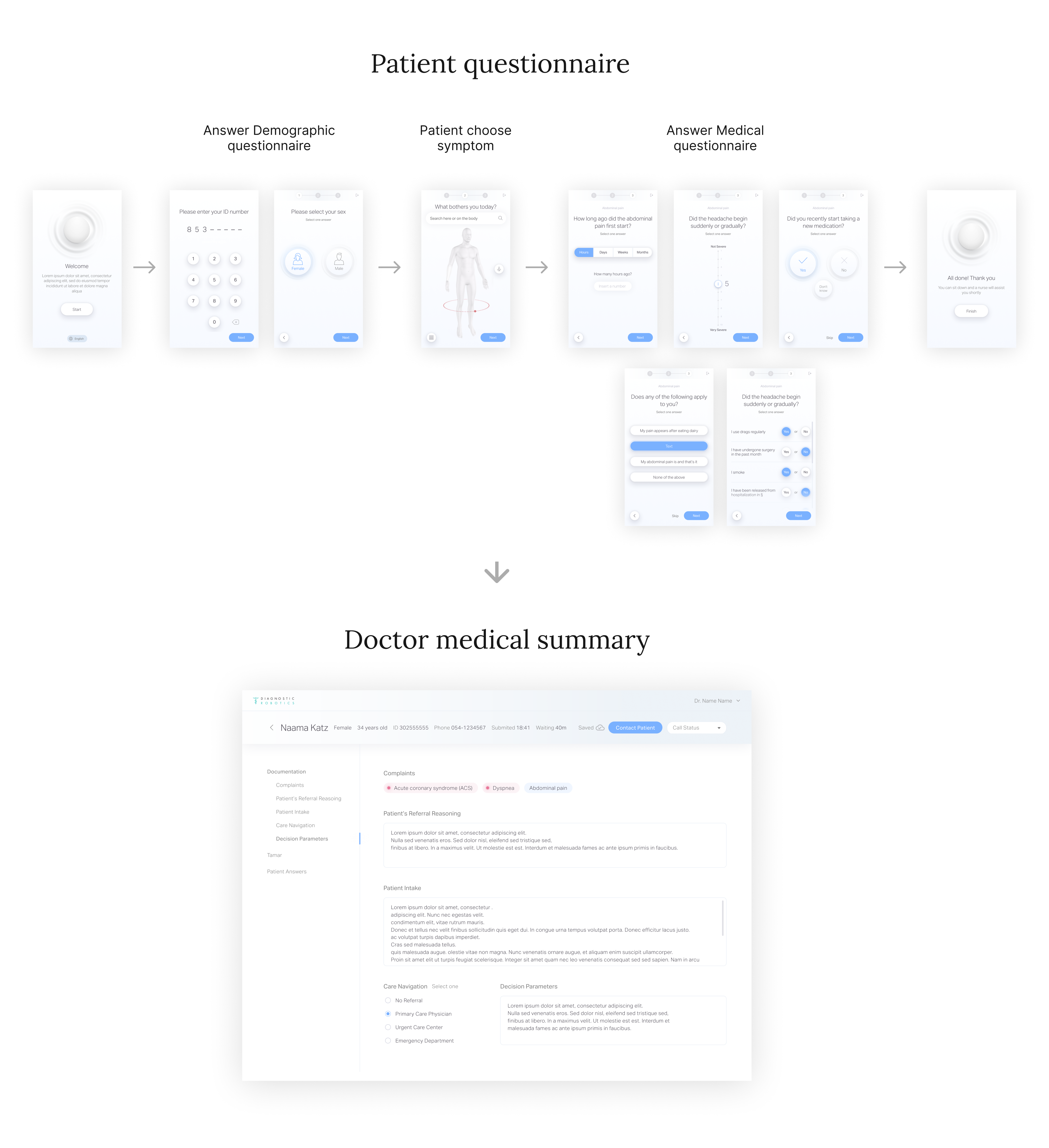
Example of medical summary inaccuracy
In a face-to-face meeting with their doctor, a patient asked about getting a second dose of a vaccine, in light of shoulder pain that appeared after the first dose.
In the digital questionnaire, he selected the symptom of a shoulder injury and arm weakness.
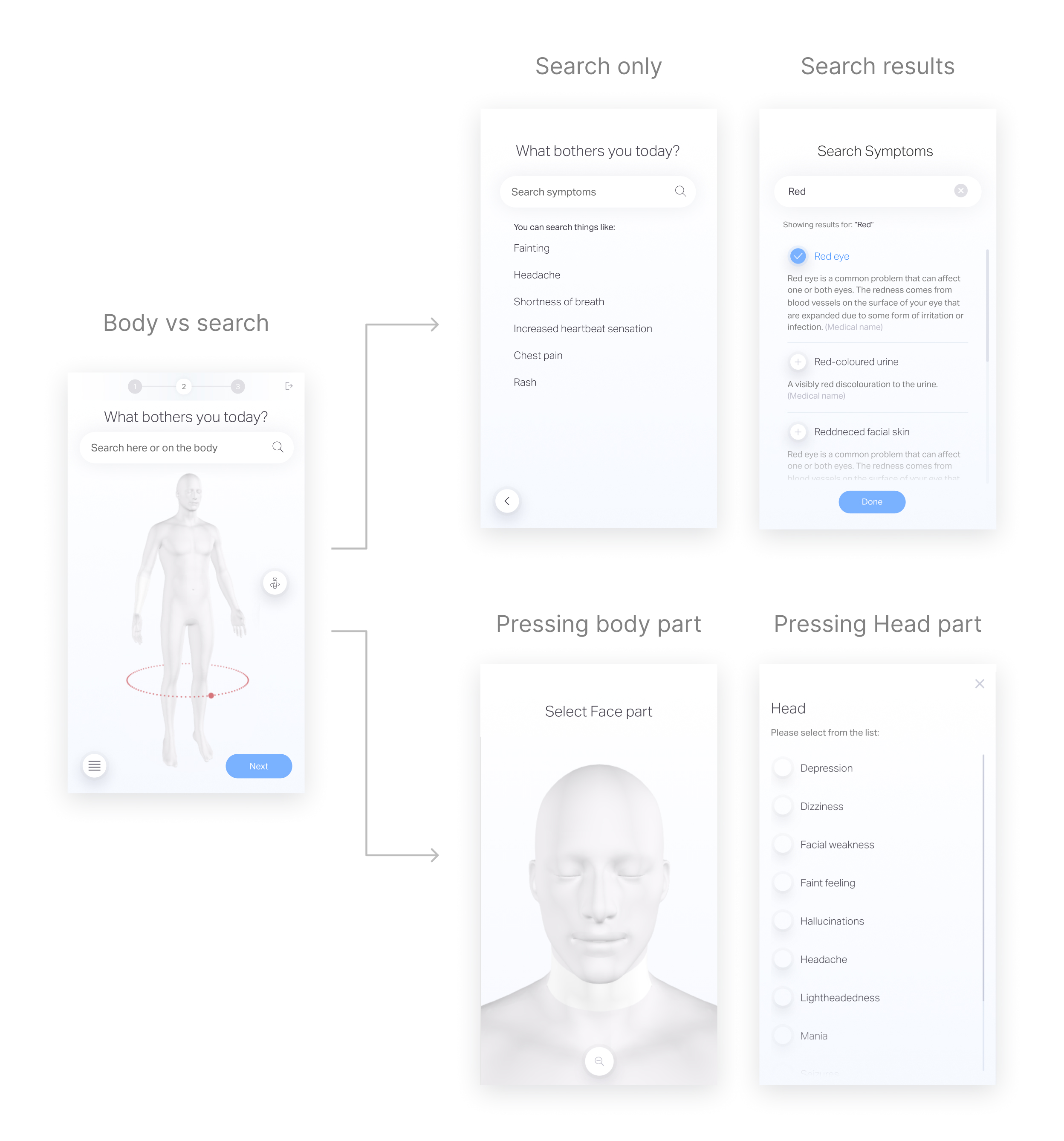
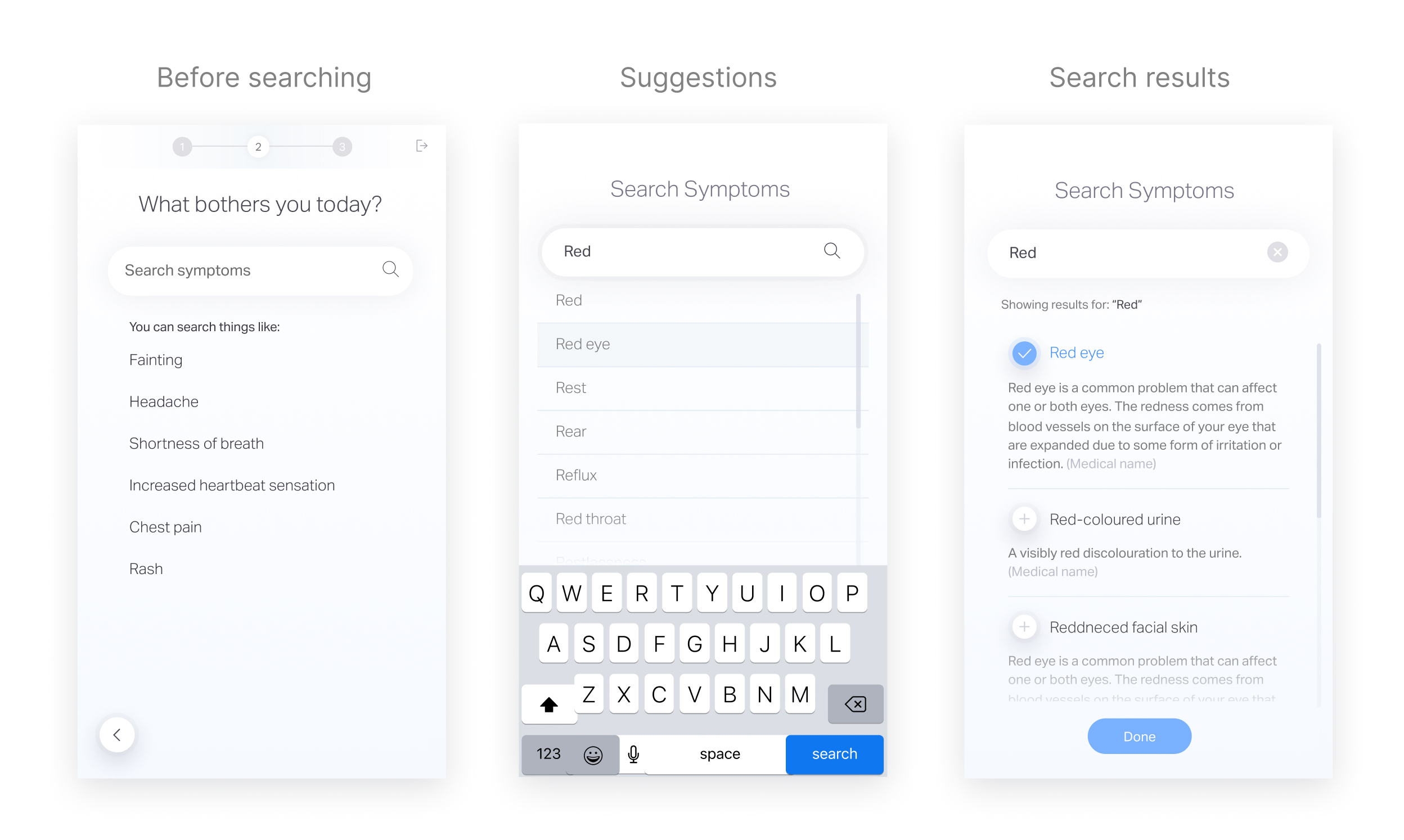
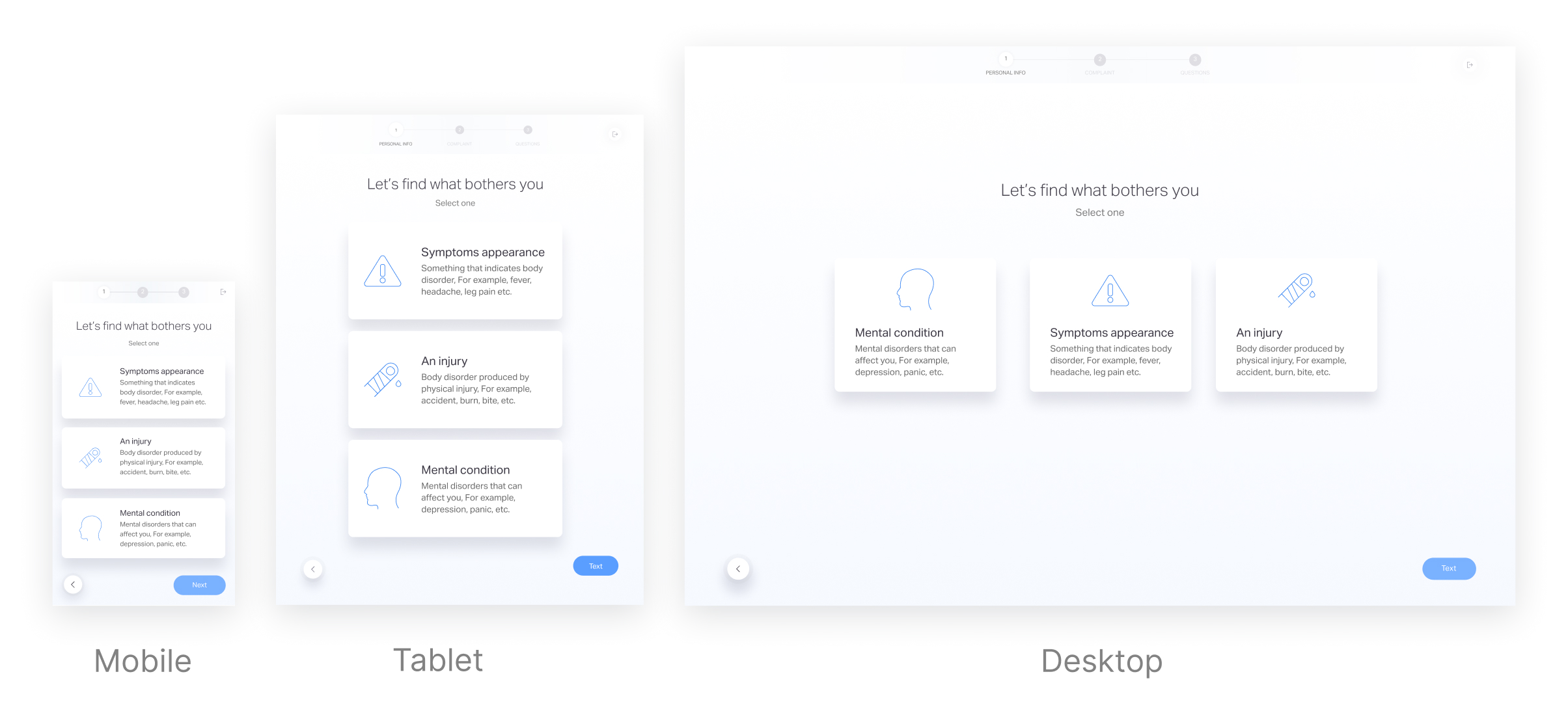
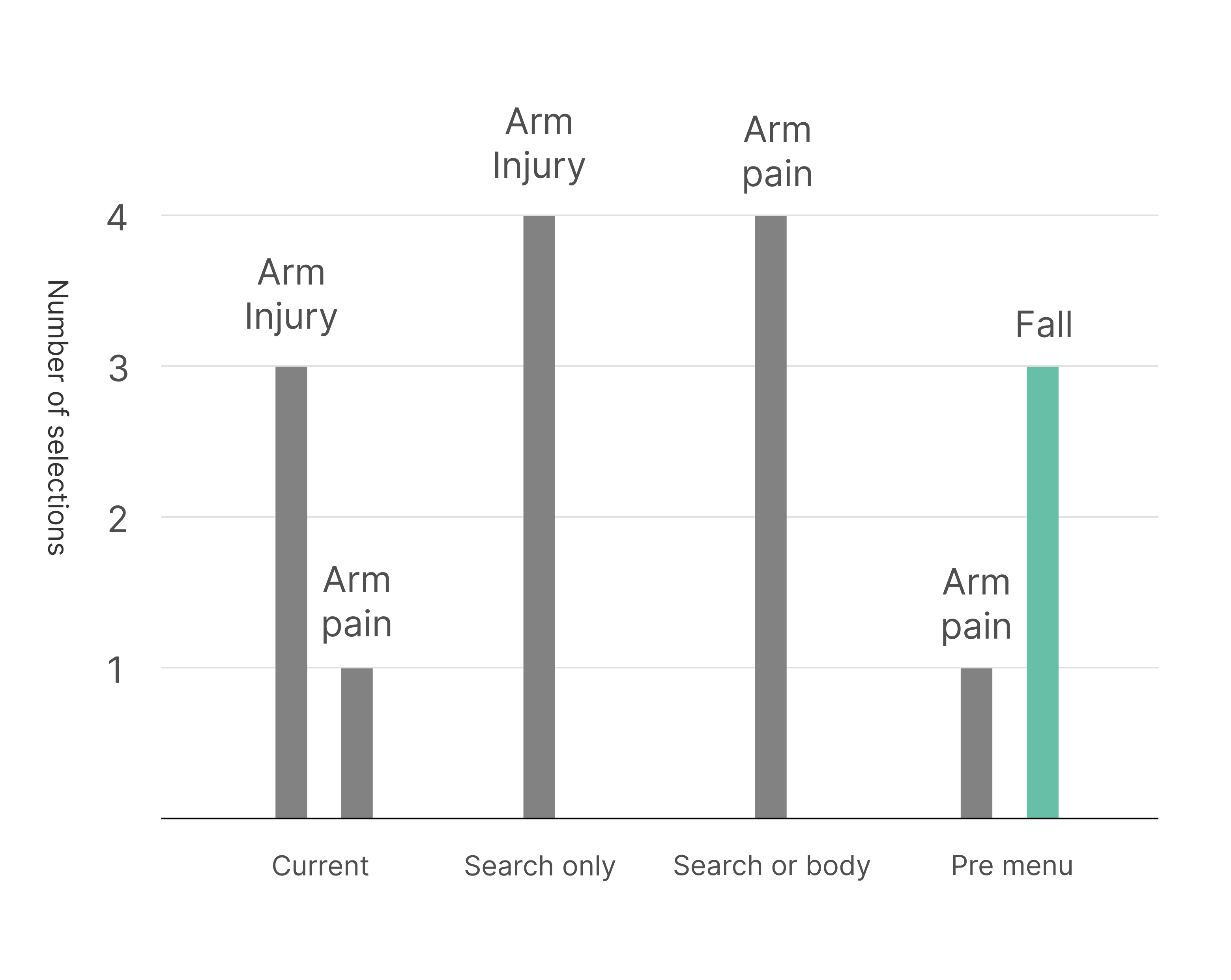
Focus on symptom selection phase
After analyzing the medical summaries, we found that some inaccuracy in the medical summaries is due to wrong selection over the symptom selection phase, which leads to a false questionnaire selection and medical summary output.
The process
- Understand the low score of medical summaries
- Shift the research to understand low symptom match
- Research symptom match
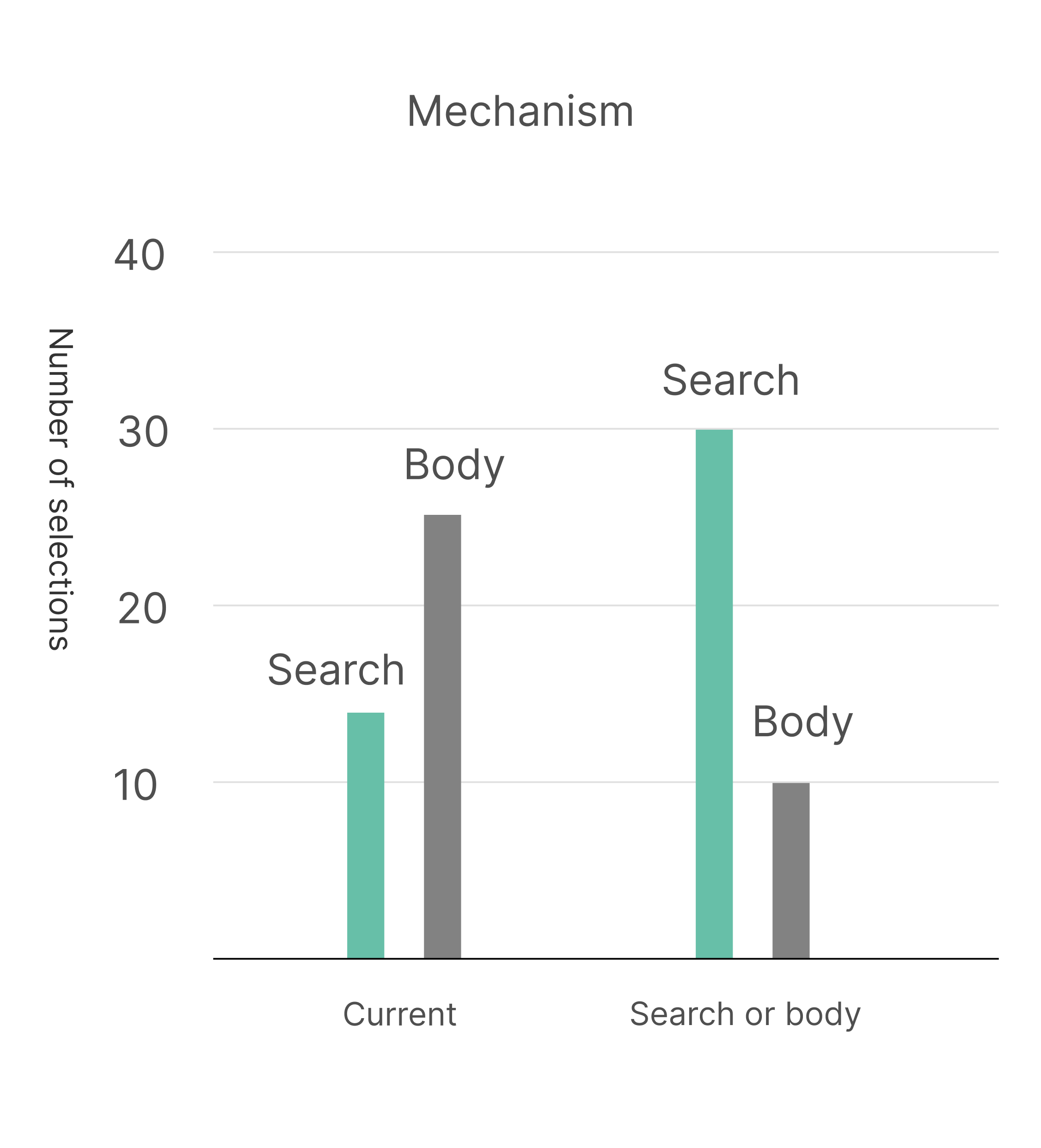
- Assume symptom match issues and ideate solutions
- Test the solutions
- Implement the solutions that improved symptom match